![]()
![]()


在今年的CIKM会议上,我们团队的一篇论文“Learning to Extract Conditional Knowledge for Question Answering using Dialogue”以长文的形式被录取。这是一篇关于条件性知识库搭建并用于驱动自动对话系统的文章。选题之初我们发现现实生活中很多人机对话往往是由于条件不足而引起的,比如在预订车票的对话中,常常会因为用户在发起订票命令时,缺少“时间”,“地点”,“人名”等条件,因此智能助手会主动提问,从而导致长对话的产生。相同的应用场景还有预定会议室、购买手机等场景。然而在目前的对话系统中,这些所谓的条件往往都是人工提前设定好的,只要系统检测到用户没有提供这个条件就会主动发问。然后每个场景的条件往往很不相同,这就会需要大量的人力来手动提取条件。
基于此,我们提出从问答语料库中自动抽取条件性知识库用以支撑人机对话。传统的知识库或知识图谱以三元组形式保存,即(主语,谓词,宾语)。本文提出的条件性知识库的形式为(主语,谓词,宾语|条件),其意义在于在给定主语和谓词不变前提下,宾语会根据条件的不同而不同,下图为我们运行实例框架图(图中假设选定windows 10为主语),抽取条件性知识库的整个框架主要由四部分组成:
模板挖掘(pattern mining)。这一步目的是从大量的问题答案对中抽取模板(pattern)。一开始我们项目处理的数据是整个开放的数据集,后来发现后续处理难度实在太大了。最后我们采取复杂问题简单化,先选取“how to”等简单句型进行处理,扩展到更多的句型乃至整个数据集是我们下一步的计划。
条件以及模板表示学习(condition and pattern representation learning)。这一步表示学习是为了给下一步聚类做准备。
条件以及模板聚类。一开始我们采用最简单的k-means方法聚类,但是发现结果非常不好,但是我们发现条件和模板共同出现的现象,最后我们提出一种新的基于表示的联合聚类(Embedding based Co-clustering)的方法聚类, 该方法融合了之前学习到的条件以及模板向量表示,同时在模板和条件两个角度上聚类。
基于聚类结果,搭建条件性知识库。在得到条件性知识库后,用户输入一个问题,我们的系统首先会检测用户问题是否缺少条件,如果缺少就反问用户并让用户补全条件,最后系统返回正确的答案。

除了获奖的三篇最佳论文,大会上还有很多质量高的报告,尤为印象深刻的便是Deep Learning Application Session,整个报告厅座无虚席,会场后面很多站立的听众也是兴致勃勃。在这个Session中总共讲了四篇论文,分别为:
“LICON: A Linear Weighting Scheme for the Contribution of Input Variables in Deep Artificial Neural Networks”
“A Deep Relevance Matching Model for Ad-hoc Retrieval”
“A Neural Network Approach to Quote Recommendation in Writings”
“Retweet Prediction with Attention-based Deep Neural Network”
下面我们简单分析一下第二篇关于信息检索的论文。
“A Deep Relevance Matching Model for Ad-hoc Retrieval”
文中提出一种新的深度网络模型(DRMM)来解决Ad-hoc信息检索任务,计算query和文档(document)的相关度在信息检索中非常重要。该文对比了在计算相关度中有用到的两种深度网络结构:Representation-focused模型和Interaction-focused模型。Representation-focused模型中具有代表意义的模型有DSSM、 CDSSM以及ARC-I;Interaction-focused模型中具有代表意义的模型有ARC-II。该论文是在Interaction-focused模型基础之上进行修改,得到一个新的网络模型DRMM。之前的基于Interaction-focused的模型保留了位置信息,比如ARC-II中生成的交互矩阵,然后在此之上构建前向网络。但是在实际情况中,query中的词和文档中的词不具有位置上的对应关系。基于此,该文提出的DRMM是基于值的大小对matrix中的单元重新分类(即该文中所提到的直方图)。该文首先用query中的每个单词和文档的每个单词构建成为一个词对(word pair),再基于词向量,将一个词对映射到一个局部交互空间(local interactions,该文用了余弦相似度)。然后将每一个局部交互空间映射到长度固定的匹配直方图中。引用文中的例子,将相似度[-1, 1]分为五个区间{[-1,-0.5), [-0.5,-0), [0,0.5), [0.5,1), [1,1]} 。给定query中的一个词“car”以及一篇文档(car, rent, truck, bump, injunction, runway), 得到对应的局部交互空间为(1, 0.2, 0.7, 0.3, -0.1, 0.1),最后我们用基于计数的直方图方法得到的直方图为[0,1, 3, 1, 1]。对于每一个query的词得到一个直方图分布后,在此之上构建一个前向匹配网络并且产生query和文档的匹配分值,最后在将query中所有词合并的时候加入gating参数(比较类似于attention机制),整个框架图以及实验结果如下图所示。研究信息检索的读者可以仔细阅读一下全文。



另外Question Answering Session中也有两篇高质量的论文,一篇即为获奖论文(医疗问答),下面简单介绍一下另一篇。
“aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model”

Hub解封,“开放知识”有多远?
埃尔巴金(Alexandra Elbakya)发文的9月5日,也是Sci-Hub网站成立的十周年纪念。埃尔巴金还表示,...(240)人阅读时间:2021-09-13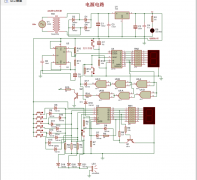
六人竞赛抢答器的电路设计详细论文资料
六人竞赛抢答器的电路设计详细论文资料免费下载,电子发烧友网站提供各种电子电路,电路图...(251)人阅读时间:2021-09-13
代写高校教学论文与科研关系的浅析
论文关键词:非研究型大学 教学 科研 论文摘要:针对高校,主要指非研究型大学的过度重科...(232)人阅读时间:2021-09-13
怎样找到专业代写发表教学论文的机构
教学论文就是讨论和研究有关教学问题的文章,发表教学论文也是教师评职称的必要条件。在...(213)人阅读时间:2021-09-13
找人代写数学教学论文(成功经验)
由于很多数学老师忙于平时的生活和工作,没有时间完成论文写作,找人代写论文变成了很好...(246)人阅读时间:2021-09-13

