
时间:2025-04-29 15:42 | 来源:墨客学术 | 作者:墨客学术 | 点击:次
探索信息检索的未来:我院发布生成式信息检索综述 日期:2024-05-06访问量:
在数字化时代,信息检索(IR)系统已成为我们获取知识、解答疑问、发现内容的重要工具。从谷歌搜索到智能问答系统,再到个性化推荐平台,IR技术无处不在,它们不仅提供信息,更是我们日常生活中不可或缺的工具。
传统的IR系统依赖于关键词匹配和文档排序,但随着预训练语言模型的兴起,一种全新的检索范式——生成式信息检索(GenIR)正在兴起。GenIR通过生成模型直接生成相关文档的标识符或直接生成可靠的回复来满足用户的信息获取需求。这不仅提高了检索的灵活性和效率,还极大地提升了用户体验。
为此,中国人民大学高瓴人工智能学院的师生们对生成式信息检索的最新研究进行了深入调查,并撰写了一篇综述文章,引用或介绍了超过350篇相关论文。该文章目前已以预印本的形式发布在arXiv网站上,旨在为研究者和工程师们提供技术参考。

论文链接:
https://arxiv.org/abs/2404.14851
GitHub项目链接:
https://github.com/RUC-NLPIR/GenIR-Survey
下面将简要介绍各个章节内容,完整内容请参阅我们的英文综述。
总览
生成式信息检索(GenIR)作为信息检索领域的一个新兴方向,其核心在于利用生成模型来实现信息检索的功能,而不是通过如图1(a)所示传统的相似度匹配方法。这种方法在处理用户查询时更为高效,因为它能够直接生成贴合用户需求的信息,而不需要用户在检索结果中进行筛选,再总结想要的答案。
GenIR的研究可以分为两大类:生成式文档检索(Generative Document Retrieval, GR)和可靠回复生成(Reliable Response Generation)。如图1(b)所示,GR通过生成模型的参数记忆文档,直接生成相关文档的标识符;另一方面,如图1(c)所示,可靠回复生成则利用语言模型直接生成用户所需的信息。这两种方法都旨在提高检索的效率和准确性,同时为用户提供更加丰富和个性化的搜索体验。
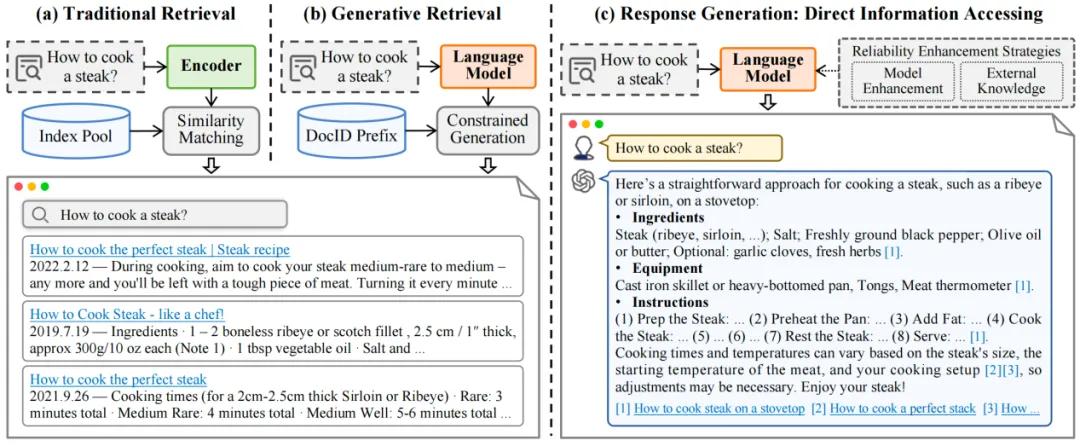
图1: 探索生成式信息检索的革新:从传统基于匹配的方法到基于生成的方法
下面是本综述的整体章节安排,涵盖了生成式文档检索、可靠回复生成、评估、挑战和前景:
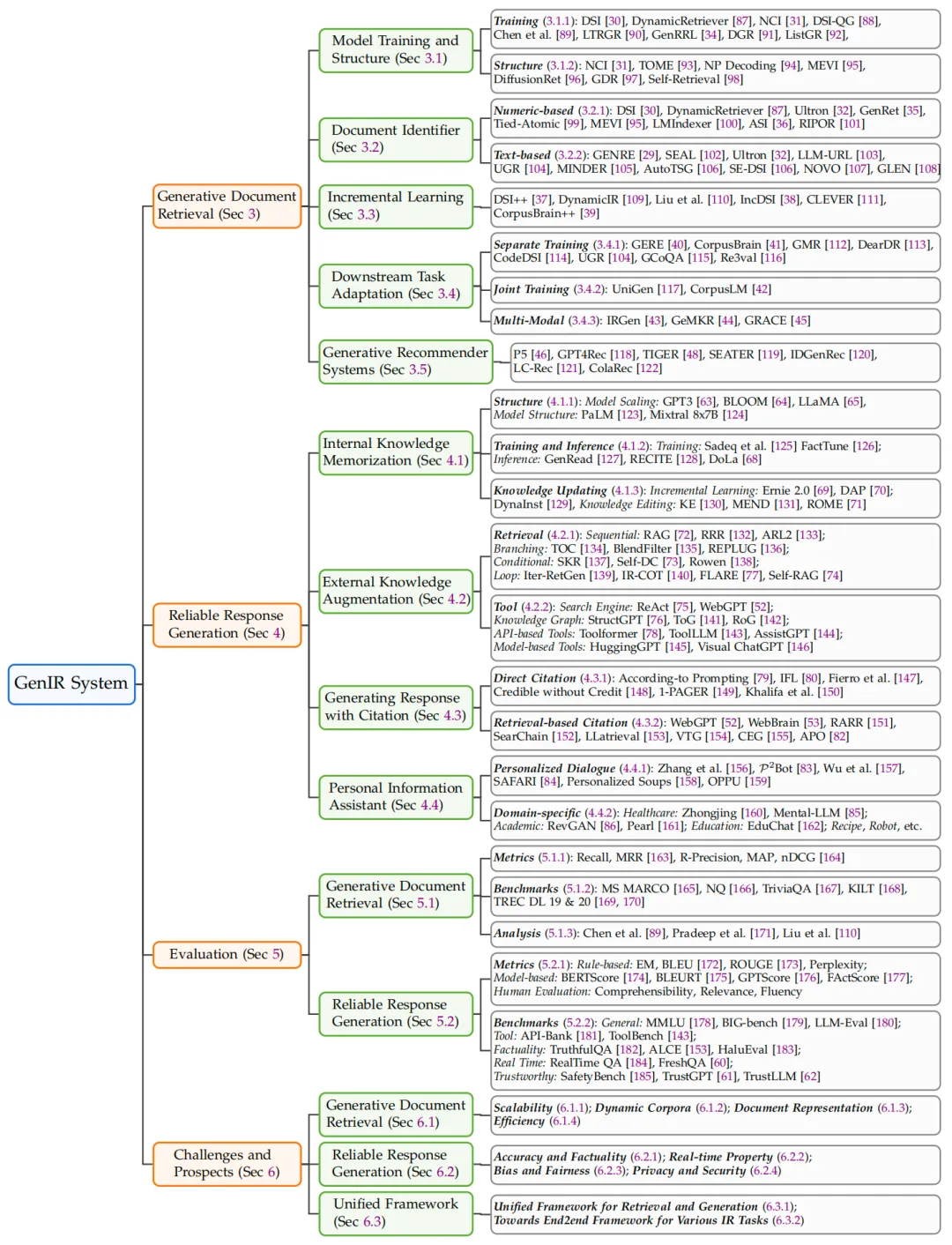
图2: 综述的章节安排,涵盖了生成式文档检索、可靠回复生成、评估、挑战和前景
生成式文档检索:从相似度匹配到生成文档标识符
在人工智能生成内容(AIGC)的最新进展中,生成式检索(GR)已成为信息检索领域的一种有前景的方法,引起了学术界的日益关注。图3展示了GR方法的时间线。最初,GENRE提出了通过限制集束搜索和预建的实体前缀树生成实体,实现了优越的实体检索性能。随后,Metzler等人构想了一个基于模型的信息检索框架,旨在结合传统文档检索系统和预训练语言模型的优势,创建能够在各个领域提供专家级答案的系统。
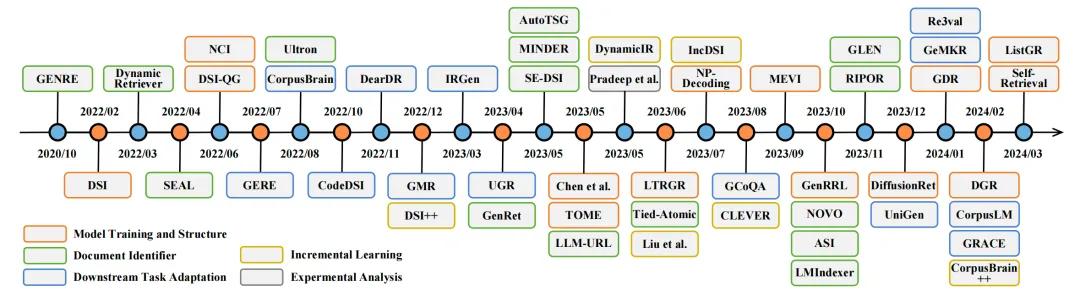
图3: 生成式文档检索相关研究的时间线
在这些工作的引领下,研究者提出了包括DSI、DynamicRetriever、SEAL、NCI等在内的一系列方法,相关工作不断涌现。这些方法探索了模型训练和架构、文档标识符、增量学习、任务特定适应性以及生成式推荐多个方面的内容。图4展示了GR系统的整体概览:
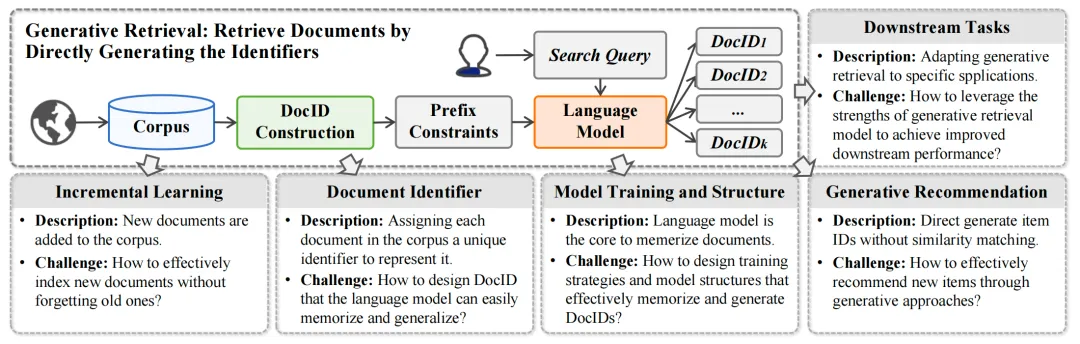
图4: 生成式文档检索的整体框架、各个模块及其挑战
我们深入讨论了生成式检索领域每个相关的研究方向,包括如下方面:
1. 模型训练与结构:GR模型的训练通常采用序列到序列(seq2seq)的方法,通过训练模型学习从查询到相关DocIDs的映射。研究者们还提出了多种数据增强和训练目标策略,以提升模型的检索性能。
2. 文档标识符:GR系统中的文档标识符(DocIDs)可以是数字序列或文本序列,它们作为模型的输出目标,帮助模型记忆文档内容。设计DocIDs的方式对于模型能否有效记忆和检索文档至关重要。
3. 增量学习:随着文档语料库的动态变化,GR模型需要能够增量学习新文档,同时保留对旧文档的记忆。研究者们开发了多种方法来优化模型以适应动态语料库。
4. 下游任务适应:GR模型不仅可以用于检索任务,还可以适应各种下游任务,如事实验证、实体链接、开放域问答等。
5. 多模态生成式检索:GR模型还可以结合多模态数据,如文本和图像,实现跨模态的检索。
6. 生成式推荐系统:基于GR的思想,推荐系统也可以不基于传统的匹配的方法,直接生成推荐物品的ID。